
A few weeks ago I was tasked with importing data into a system we had built on top of Elastic. At this point I was very happy with Elastic, how it performed along with all the cool indexing features it brought to the party.
For those that don’t know, ElasticSearch is a document store, which indexes the documents in such a way that retrieving them is super quick, which is exactly what I needed.
We are using the managed cloud version of Elastic from elastic.co. The great part about it is that you don’t need to work very hard to get your cluster setup and encryption at rest security.
My initial tests using the Elastic bulk API and with small data-sets ranging in the few thousands were positive, however they did take a fair amount of time as my strategy was fairly cumbersome and hacky.
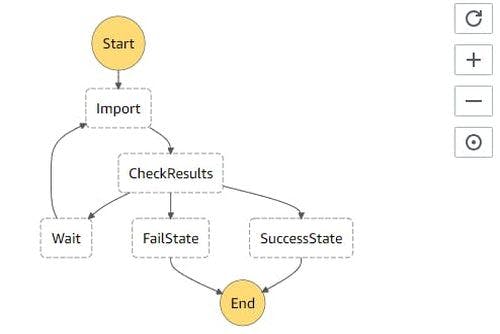
My next strategy to import the data was to use a recursive AWS Step function running a lambda function in the backend.
Fairly straight forward, the import rule however has an exponential back-off timer on errors and I wait 30 seconds between each run just to let the data settle.
The biggest problem I faced here was the rate at which I was pushing data into elastic, considering my instances had a maximum queue size of 200 with 2 worker threads each.
My Lambda function took the form of: [S3 File Stream] => [CSV Parse] => [Custom Data Mapping and Cleansing] => [Data Storage] => [Analytics Collection]
My initial concurrent tests weren’t bad, I was importing about 60 000 records every minute.
creds:giphy.com
But this spurred me onto moving towards parallelism to get the data in faster, no one likes waiting for their data!
This is when my schooling in NodeJs streams began and my realization of how little I knew at the time. I was attempting to manage backpressure using limits on my Lambda function, the other problem I faced here was that the Lambda function could time out at any point, so I wrote highly convoluted logic to try and prevent all of this, destroying streams and storing buffer bookmarks, accounting for streams being at different points in their read and write cycles.
Using Lambda and Step functions I could initially load data into elastic at around 400 000 records in 30 seconds, which was great but it also seems I was ignoring that some of my logic was incorrect and that elastic was fine with this magnitude of data at the beginning of an index but when you are using the <Update API> for everything, things start getting a little hairy.
Logstash
My latest strategy was to offload some pressure from myself and ditch the lambda functions as they were just complicating the whole thing. At this point I asked myself why not use Logstash? So off I went on a tangent trying to get Logstash working on an Ubuntu EC2 instance and after fiddling with it for much of a Saturday morning, I finally got it working:
input {
s3 {
"access_key_id" => "<ACCESS KEY>"
"secret_access_key" => "<SECRET ACCES KEY>"
"bucket" => "<LE BUCKET>"
"region" => "eu-west-1"
"codec" => plain { charset => "ISO-8859-1" }
"additional_settings" => {
"force_path_style" => true
"follow_redirects" => false
}
"sincedb_path" => "/dev/null"
}
}
filter {
csv {
autodetect_column_names => true
skip_empty_rows => true
}
}
output {
elasticsearch {
hosts => ["<elastic host>"]
user => "<username>"
password => "<user password>"
}
}One thing is quite interesting here ”codec” => plain { charset => “ISO-8859–1” } . The files that I was receiving were dumped from a MS SQL 2012 instance. This was due to legacy systems running off this database, what the file dump had done was it had encoded it as Unicode(MS SQL default) and not the preferred Utf-8. After this change I could eventually start running my pipeline.
Much to my dismay, the first 3Gb file which I could not edit had a header that was misplaced, so all my subsequent data was skewed and assigned to the wrong properties. At this point I was not willing to write a grok filter to clean my csv file as I didn’t know what else was going to come out the woodwork once I started digging deeper.
Don’t get me wrong, Logstash looks like an awesome tool and I will definitely be using it in the future, just not for this particular use case.
My final attempt
Having already setup my Logstash EC2 instance, I figured why not just write a straight forward NodeJs app to do my bidding. I stripped out much of the logic I had for restarting my import processes, so that everything could run in just one go.
Back to backpressure
My original code included 2 Transform streams which I piped parsed csv objects into. The first does mapping, cleaning and runs some functions to extract other data from each record. The second batches these records into batches of 1000 elastic records and creates a promise to push them to Elastic.
What I hadn't realised is that Transform streams can actually manage their own back pressure using their callback methods. I tinkered with this and eventually got my pipeline working, this was only after I split up my streams instead of piping each one into the next. What it seems like was happening was that I was creating backpressure and because of this, the other streams had gone into a paused state. This in turn made my NodeJs app suddenly exit as there was nothing to do because my Promises had all resolved at this point
Splitting the streams up like this allowed each stream to manage its own backpressure and allow my process to continue.
const fileStream = getFileStream( key, bucket, start_at_bytes, objInfo.ContentLength ) const mapStream = fileStream.pipe(parser).pipe(dataMapper) const dbStream = mapStream.pipe(dataStorage) //Get the party started! dbStream.resume()
Optimising for Index operations
Elastic has a nice page outlining how to optimise your instance for index calls Index Tuning. Using this new found information I made some adjustments to my indexes.
PUT fake-index-name-here
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"refresh_interval": -1
}
}
}What an index normally does is that it refreshes every 1s, this is nuisance when loading this magnitude of data and setting it to -1 optimizes index writes. The other thing here is the number of replicas, each replica has to have the data written to it at some point, but setting it to 0 allows you to write to only 1 instance increasing your index performance!
This worked wonders as I had pumped in 16 000 000 records in the space of just a few minutes!
But as I hit that milestone things started slowing down exponentially, I scanned through my code and the link provided and found that I had been using the Update API all along as each record was always unique and I wanted to keep it that way.
What the Update API does is it looks for the ID you just inserted and tries to update, setting docasupsert will then insert the document if it doesn’t exist which is great for re-running your import procedure, but super bad for inserting a whole bunch of new data into a large index!
I then changed to using the index API, but the same still occurs, elastic searches for the ID you specified and checks for a conflict, the solution, REMOVE ALL THE IDs!
After removing the explicit _id on my bulk indexes I have thus far managed to insert 16 000 000 records in 15 minutes.
My total run time was approximately 4 hours for the full dataset, but this was caused by a completely different reason.
Limitations
After all my experimentation with Elastics cloud offering and using underlying AWS resources I found that my servers were running out of CPU credits, this was visible at around the 16 000 000 record count with some simple-ish data
Using Elastics Performance monitoring section of my deployment I could see that I was running out of CPU credits fairly quickly, the graph below was extracted after the fact, but the results are visible.
After doing a bit of research I discovered this in the AWS EC2 documentation:
One CPU credit is equal to one vCPU running at 100% utilization for one minute. Other combinations of number of vCPUs, utilization, and time can also equate to one CPU credit. For example, one CPU credit is equal to one vCPU running at 50% utilization for two minutes, or two vCPUs running at 25% utilization for two minutes
Turns out that 16 000 000 records took approximately 15–16 minutes to import, the elastic node’s CPU is running at 100% and I have roughly 16 CPU credits on the nodes I procured for my Dev environment
The above cluster is across 3 availability zones with 2 Gb ram each. I have since then modified the cluster to be across 2 availability zones and increased the ram to 4 Gb. This then gave me roughly 3000 CPU credits, and for the next set of data instead of using 1 shard I have now used 2.
The reason for this is that Elastic will automatically place the second shard onto the other node of my cluster and then using elastics internal id generator for my documents, there is enough randomness to the ID that it places my documents across both shards, this allows me to get an effective 6000 CPU Credits
I have also adjusted my ETL process to set my batch size to 250 records per batch, this equated to ~10 000 000 records imported in 5 minutes.
I am quite happy with the results I am now getting. My next issue is how to deal with re-indexing my data into a format that I am comfortable with as my various pieces of data are now placed across multiple indexes.
I may even keep it in this format as I will need to augment this data with future updates and uploads. In terms of maintenance it seems far easier leaving it in this state, I will make my decision based on the code to query each of these entities. I have found no simple way of indexing data with its child records as one single document as using scripts to combine the data is extremely expensive. If the data-set was a lot smaller I may consider it as a viable option but for now it will remain the way it is.
Stay tuned for my next adventure where I have to augment my current indexes with new data from multiple different sources.